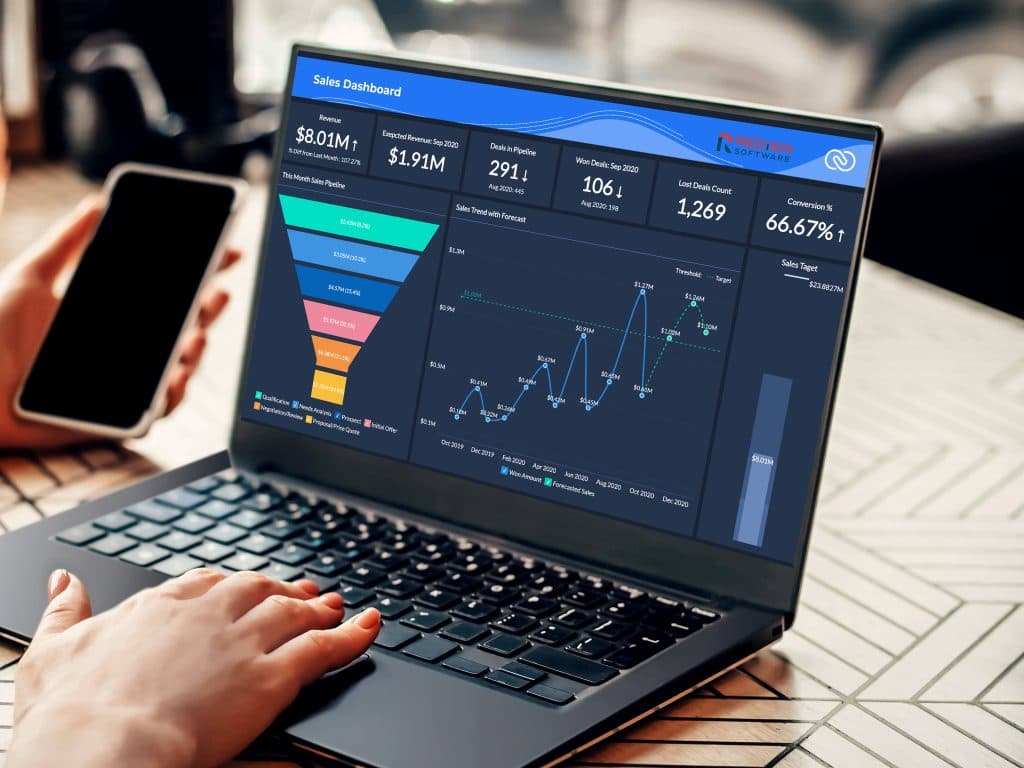
Most enterprises sit on millions of pages of contracts, KYC files, claims, policies and operational records — and almost none of it is searchable, summarised or governed. Redian's AI Document Management platform turns that static archive into a living knowledge base your teams can query in natural language, with OCR, classification, semantic search and LLM-powered summarisation built in.
What it does
The platform ingests documents from email, shared drives, scanners and core systems, then runs them through a pipeline of OCR, layout parsing, entity extraction and classification. Every document is chunked, embedded and indexed so users can ask questions in plain English and get cited answers — not link lists. Sensitive fields are auto-redacted, retention rules are enforced, and every access is logged for audit.
Where it fits
We deploy it across regulated and document-heavy operations: lending and underwriting files, claims dossiers, vendor contracts, HR records, audit evidence, regulatory submissions and customer correspondence. It pairs naturally with our banking solutions, policy administration and claims management deployments, and with our broader AI/ML practice for custom model work.
Why intelligent DMS beats traditional ECM
Traditional ECM stores documents. Our platform reads them. Underwriters ask "what is the LTV on this file and is the income proof current?" and get an answer with page-level citations in seconds. Auditors ask "show me every contract with an indemnity cap below USD 1M signed in 2025" and get an instant evidence pack. The shift is from filing cabinet to colleague.
Core capabilities
Multi-format ingestion (PDF, DOCX, TIFF, email, scans), high-accuracy OCR for printed and handwritten content, document classification across 50+ types out of the box, named-entity extraction (parties, amounts, dates, clauses), vector search with citation, LLM summarisation and Q&A, automated redaction of PII/PHI, retention and legal-hold workflows, granular role-based access, and full audit trail for every read and write.
Architecture and security
Deployed on AWS, Azure or on-prem with full data residency control. Documents and embeddings are encrypted at rest and in transit; PII is detected and masked before reaching the LLM layer. We support private model deployments (Llama, Mistral, on-prem Claude via Bedrock) for clients who cannot send data to public model endpoints. SSO, MFA, IP allowlisting and SOC 2-aligned controls are standard.
Integrations
Out-of-box connectors for SharePoint, Google Drive, S3, Box, OneDrive, Outlook/Exchange, Gmail and major core systems. We also integrate with our CRM and ERP implementations and Zoho stack so documents stay linked to the customer, claim or asset they belong to.
Why Redian
CMMI Level 3 engineering, an AI/ML team that has shipped RAG systems into banks and insurers across four continents, and delivery hubs in Noida, Nairobi, Dubai, London and New York. We build the platform, train the models on your taxonomy, and stay on after go-live through staff augmentation or managed services. See how we have delivered for regulated clients in our case studies.
Working with Redian
Engagements start with a 2-week discovery to map your document estate, classification taxonomy and retention rules. We then stand up a pilot on a single document class — typically lending files or contracts — measure extraction accuracy and user adoption, and expand from there. Most clients reach enterprise rollout in 12-16 weeks.
Talk to us
If your teams spend hours searching shared drives, or your auditors take weeks to assemble evidence packs, we can help. Contact our team for a working demo on your own document samples, or browse our case studies to see what we have shipped for banks, insurers and enterprises.